- 解を出すための理論的背景
- ここで主に行っているのは自由記述の分析です。分析と言っても、意味も含めて論理的に細かく分析しているわけではありません。人間の思考には論理的な部分もありますが、ある文脈をもとに論理を飛躍させたり、直感的に判断したりします。私自身、1990年代には論理的な部分の記述を試みましたが、限界を感じて失敗しました。ここでは、現在のデータが、すでに過去に判断されたデータのどれに近いかを検索する方法を採用しています。現在のものを一定のアルゴリズムで論理的に分析して答えを出すのではなく、過去の事例から答えを導き出すと言ってよいでしょう。そのため、過去のデータをあらかじめカテゴリー化したり(自己組織化マップ)、関係性を求めておいたり(ホップフィールドモデル)しています。そのようなたくさんのデータから、最も一致するものを抽出したり、関係性を求めたりしています。これは、コンピュータの処理速度が向上したことによって可能になったと言えます。本田氏らが指摘しているように、「コンピュータが解を出すのに複雑なアルゴリズムは必要ではなく、単にフィルターをかけてクラウドに蓄積された膨大なデータを絞り込み、整理するだけでよくなってしまった」ということになります。
引用:本田幸夫「ロボット革命 - なぜグーグルとアマゾンが投資するのか-」、祥伝社、 2014 年、 153-154
- 文章から単語の抽出
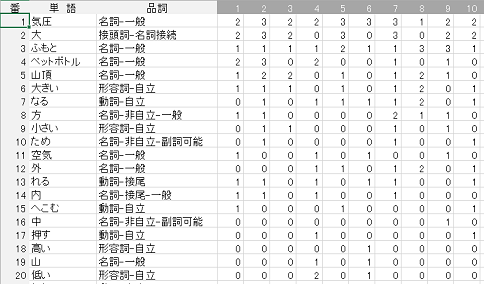
- 記述や発言内容を対象とした分析において、自己組織化マップやホップフィールドモデルを用いる場合、どちらも基本となるのは文章の中から単語を抽出することです。そのために、形態素解析ソフトを用いて文章の中から単語とその品詞を抽出します。形態素解析ソフトとして「mecab」などがあります。形態素解析では「基本形」を求めることで、同一単語の活用形による違いを検出しないようにしています。一方、品詞を求めることで、同じ単語の表記でも品詞が異なる場合の違いを検出できるようにしています。このようにして求めた単語と品詞から、重複しているものや分析を必要としない品詞の単語を取り除き、文章において使用されている単語を抽出します。

- 文章のデータ化
- 抽出した単語を行に配置し、1つの文章を列に位置付けます。その文章において抽出した単語が何回出てくるかを数字にして、マトリクスに示すことができます。ここで単語に注目すると、左図の単語「空気」は「1、0、0、10、11・・・」といった数列で表されます。今度は文章に注目すると、1番目の文章は「2、2、1、20、11・・・」といった数列で表されます。
自己組織化マップでは、単語の数列に注目すると、数列のパターンが類似していれば、それらの単語を近くに位置付けるように考えます。同様に、文章の数列に注目すると、数列のパターンが類似している文章ほど、それらを近くに位置付けるように考えます。このようにして単語や文章を整理していくことで、分析や評価に役立てることを目指します。また、本研究では、すでに数値化されている評定尺度によるアンケート調査などの回答や学力を評価した点数などを、そのまま用いることで、数値の類似度からその項目などの関連性を求めています。
ホップフィールドモデルにおいても、まず単語の数列に着目します。ある単語Aと単語Bについて、同時に用いられている度数、単語Aは用いられるが単語Bは用いられない度数、逆に単語Aは用いられないが単語Bは用いられる度数、両単語とも用いられない度数を求めます。これらの度数から単語Aと単語Bの関連(荷重)を求めるように、すべての単語の組み合わせについて算出します。この荷重をもとに、ある単語を用いたときに関連して想起されやすい単語を求めることができるため、学習補助や授業設計などに役立てることができます。
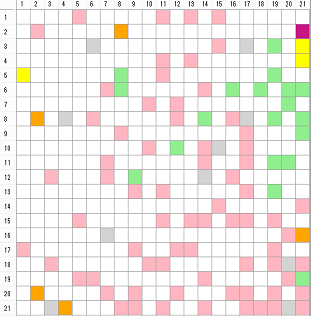
- 自己組織化マップの作成と活用
- ここでは、表現しやすいように自己組織化マップを四角いユニットの集合で示します。この自己組織化マップのユニットに文章を配置することを考えます。先ほど一つの文章を数列で表しましたが、その数値の数だけ、一つのユニットに数値が含まれていると考えます。ユニットの数値は最初はランダムに設定します。まず一つの文章を取り上げ、その文章の数列とユニットに設定した数列を照合し、最も一致しているものを一つ選びます。ユニットの数列の値はランダムに設定していますが、その中でも最も一致するユニットを一つ選ぶことができます。そのユニットに文章を配置するとともに、ユニットの周辺、たとえば前後左右10個先のユニットの値を、数パーセント配置されたユニットの値に近づけるように変更します。次に別の文章を1つ選び、同じことを繰り返します。1つの文章が数百回程度選択されるまで繰り返します。繰り返しが進むにつれて、値を変更する周辺ユニットの範囲を狭めていきます。このように、それぞれの文章によって全体のユニットの値が変化するため、同じ文章でもその都度配置されるユニットが変わります。しかし、繰り返すことで全体の構造が、類似した文章が近くに集まるように変化していきます。左図では、色の付いたユニットに文章が配置されていますが、例えば正答や誤答の記述によってユニットの色を変えるなどして示すことができます。単語を配置する場合も、単語の数列を用いて同様に処理します。
このように最初から全体の基準や構造があってデータを配置するのではなく、また、個別のデータに基づいてその値を順序よく並べるものでもありません。全体の構造はデータによって変動し、各データは全体構造によって位置付けられるという、全体と部分の相互作用によって処理が行われる特徴を持っています。よく「縦軸や横軸は何を表すのか」といった質問を受けますが、同じようなものが近くに集まるだけで、あるユニットAとその近くのユニットBの類似性と、さらにその近くのユニットCの類似性の基準は異なります。そもそも、2次元で表現しているので、そのような軸が明確にある場合は、こうした分析をしなくても見ただけで気づくと思います。2次元では表現しきれません。何か軸を探そうとするのは因子分析などの影響だと思いますが、因子分析でも、だいたい経験的に分かっているような因子が分析によって明確になるだけで、誰も気づいていない画期的なものが見つかったということは、自分の経験ではあまりありません。
このように文章を配置した自己組織化マップには、新たに記述した文章を位置付けることができます。まず新たに書いた文章を形態素解析して単語を抽出します。自己組織化マップを作成したときの単語をもとに、新しい文章を数列で表します。その数列と自己組織化マップの全ユニットの数列を照合し、最も一致するユニットを選びます。そのユニットに位置付けられた文章が、新しく記述された文章と最も類似していることになります。例えば、その選ばれたユニットの文章が正答であれば、新しく書かれたものも正答である可能性が高いと言えます。このようにして、自由記述の回答を自動で評価するシステムなどを作ることができます。
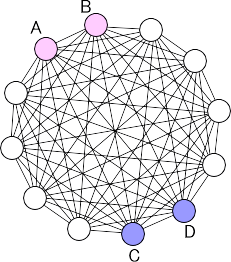
- ホップフィールドモデルの作成と活用
- ホップフィールドモデルでは、すべてのユニット(〇)が連結した構造を考えます。一つのユニットに一つの単語を配置します。つまり単語間はすべて連結していますが、その連結の度合いに荷重を用います。荷重は関連があれば正の大きな値になり、関連がなければ負の小さな値になります。ホップフィールドモデルを用いて、連想記憶モデルを例に動作と活用を考えます。まず、左図の
A と B のユニットに対応した単語を刺激語とします。ここは常に「 1 」の値を出力します。他のユニットは最初「 0 」の値を出力します。すべてのユニットは連結しているため、信号が全ユニットに伝達されます。この伝達においては、それぞれのユニット間の荷重がかけられます。荷重は正の値も負の値もあるので、あるユニットに来る信号をすべて合わせると、正になる場合も負になる場合もあります。そこで、
A 、 B 以外のユニットをランダムに一つ選び、そこに来る信号の合計が「 1 」以上であれば、そのユニットは「 1 」を出力し、「 1 」以下の場合は「
0 」のままにします。次に、またランダムにユニットを一つ選び、そこに来る信号の合計が「 1 」以上であれば、そのユニットは「 1 」を出力し、「
1 」以下の場合は「 0 」のままにします。これをユニットの出力に変化がなくなるまで何度も繰り返します。その結果、最終的に C と D のユニットが「
1 」を出力するようになったとします。これに対応する単語が、想起される単語と見なすことができます。例えば、「天気」「雨」を刺激語とした場合、「低気圧」「前線」といった単語を想起することになります。教科書の内容でこのようなモデルを作成した場合、ある単語を刺激語として出力される想起語から、授業において関連付けて学習する内容の確認ができ、学習設計などに活用することができます。